Sometimes it feels more productive to trudge through medial clean up tasks than it does to step back and assess the utility of your project's code and knowledge base's organizational scheme. Never thought about how to organize a project's code base? Is knowledge base a strange concept, something probably taken care of by the absurd storage size of your email inbox? If you answered yes to either of these patronizing questions this post is for you.
In this post
- Attempt to convince you that subversion can make your life easier
- Walk you through installing the necessary software (easy don't worry!)
- Show you how to set up a project using a free subversion repository from assembla.com
- Go over the basics of using subversion at the command line
- Provide an alternative for those less comfortable working at the command line by demonstrating how to use a popular OSX subversion client.
Why use subversion?
Because your busy. You want a way to track the progress of your project. You don't want code that you spent time, sweat, and tears on getting lost, out of date, or unknowingly mucked up by some undergraduate assistant (guilty). Subversion is a free software versioning and revision control system that can help if you have ever done any of the following:
- Made a change to code, realized it was a mistake and wanted to revert back.
- Lost code or had a backup that was too old.
- Had to maintain multiple versions of a product/project.
- Wanted to see the difference between two (or more) versions of your code.
- Wanted to prove that a particular change broke or fixed a piece of code.
- Wanted to review the history of some code.
- Wanted to submit a change to someone else's code.
- Wanted to share your code, or let other people work on your code.
- Wanted to see how much work is being done, and where, when and by whom.
- Wanted to experiment with a new feature without interfering with working code.
- Wanted to know exactly what code and data produced a particular figure.
- Wanted to make your work more reproducible.
Complete thread on StackOverflow where developers describe how subversion/version control changed their lives more than magic beans changed the life of Dr. Oz.
But I'm a scientist not a software engineer!
I have never met a scientist who has not run into any of the scenarios listed above above. Copying directories and time stamping them is not the same as version control. This method is prone to errors. It also lacks the convenience offered by Subversion.
Getting started
You're busy
, so my start up instructions will be brief but if you think reading about version control technology is the most exciting thing you can do indoors you can read many more details
here.
Getting subversion on your machine
Instructions vary depending on what type of machine you are using. If you work in a windows environment the best instructions are use
Git, subversion is probably not the right version control tool for you.
For Mac users using OSX > 10.6 version control can be installed two easy ways. 1) Download
Xcode in the app store. This requires a free Apple developer
user ID. Once Xcode is installed you still need to download "command line tools". After opening Xcode 4 or 5 click "Xcode" near the apple button and select "preferences". Click on the "Downloads" tab and install the command line tools. OSX versions 10.6 and older come with Subversion installed.
2) If you don't plan on using Xcode and aren't interested in the extra baggage, you can download the command line tools separately from Apple. Your Apple ID will be required to go to the
download page. Scroll down the list until you find the Command Line Tools and download.
For Linux users: Linux platforms come with Subversion installed. To confirm you have Subversion type at the command line
which svn
If subversion is installed it will show something like
/usr/bin/svn
If subversion is not installed (very unlikely) you can find your platform and download subversion
here.
Terminology and work cycle using Subversion
Now that Subversion is installed and we are ready to set up a project lets go over some terminology and briefly describe the version control work flow.
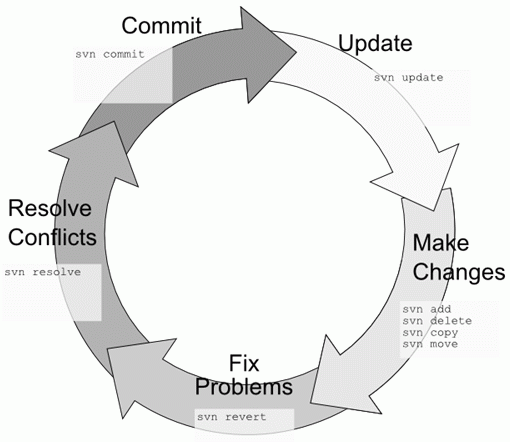
All of your files will be stored at a private URL, the location where this data is stored is the repository. The files that you first load to the repository and work on locally on your machine are called the local working copy. Each file will have a version associated with it. When you make changes to a file and want to move forward with those changes you commit that change and the version of the file in the repository will change. All versions of that file that have ever been committed will be saved in the repository. When you make changes to the files in the repository by committing new code, collaborators will be able to update their local working copy to your latest version using update. If you or a collaborator see a mistake you made and don't like a new version that was committed you can revert to a previous version. If you and a collaborator both make changes to the same piece of code you will have to resolve differences between the two conflicting versions. Subversion offers a line by line comparison to make merging changes as easy as possible. More commands will be covered below.
Setting up a project
Subversion requires a repository. This is where all project files and versions are stored. Its possible to use your own machine, or a machine in a local network but this post is for busy scientists not system administrators. The fastest way to get started is to use a free online repository by making a free account at assembla.com. Assembla is a secure Massachusetts based company that provides free (and paid) online Subversion repositories. It is also ridiculously easy to use. In June 2013 I got a group in the Atmospheric Sciences Department at the University of Washington to start using Subversion using an Assembla repository. You too can take this bold step!
To create a free account navigate to
https://www.assembla.com/sign-up and sign up for a free account. The free account is limited to two collaborators, one project, and 500 MB of storage. When you get to step three make sure to choose the "Add a Subversion Repository" option. This web interface provides the perfect place to build a knowledge base for a project. Once your free account is set up and you are logged in, at the top of your project homepage you will see a menu that looks like this

- SVN: This tab is where your project code and files will live. We will populate this in a minute.
- Tickets: A place to document tasks required for your project. A great place to throw instructions you might have been given in an email or create a roadmap for a project
- Wiki: This is a good place to provide everything a collaborator might need to know about a project. Think of it as the three minute way to introduce a new user to a project. I like to include useful links, contact information, contracts/proposals.
- Messages: A place to post messages for all collaborators to see.
- Stream: Shows project activity, including changes to tickets and files. You can monitor what time changes are made, who is making changes, and what exactly they changed each time they committed code.
- Team: Where you add collaborators and change permissions.
- StandUp: A tool for creating project reports
- Files: Location where files not under version control can be uploaded and shared
- Admin: Change account settings, upgrade, delete, etc.
Under the SVN tab you will see the name of your project and a box next to it with a URL containing your project name. That URL is where all of your project files will live. The URL is password protected so only you and your invited teammates have access. The SVN tab starts with the standard Subversion organizational scheme of /trunk /tags and /branches directories.
- /Trunk Directory where you work on the latest copy of your project. This is where you and your collaborators will change files by "committing" code in your local working copy (explained in a minute).
- /tags This directory is where you save an instance or some state of a project. Say you are about to add a collaborator or make a major change to your code that could end up breaking things. Before these kinds of events you may want to "tag" the code. This will save the current state of the trunk at a unique URL under /tags (I will show you examples).
- /Branches Directory for the project when it starts to deviate from the original plan in the Wiki.
Time to fire up the terminal, we are going to use some svn unix commands to get started. To place an existing project in the Trunk we are going to use the svn import command.
svn import /path/to/project/on/your/computer https://subversion.assembla.com/svn/YOURPOJECTNAME/trunk -m "Initial Import of existing project files."
You will see the files uploaded one at a time. The -m is to add a message to the commit. Subversion requires a message any time a change is made to the project URL. Now if you take a look at your Assembla SVN tab under trunk you will see all the files of your project. /path/to/project/on/your/computer is not a working copy. In order to start working on your project files under subversion you need to create a fresh working copy. To create a working copy you need to use the checkout command.
svn checkout https://subversion.assembla.com/svn/YOURPOJECTNAME/trunk
These files are under version control. Changes made to these files can be reflected in the repository trunk. Now we will go over the basic tools required to work on a project. The following instructions have been taken from
http://svnbook.red-bean.com/. This website is an excellent resource for anyone planning on working with Subversion long term. Below is a slim and trim outline of the subversion work cycle as described by svnbook.
The typical work cycle using subversion looks something like this:
Update your working copy. This involves the use of the svn update command. This command ensures that you are working on the latest version your projects files. If anyone else has made changes, or you made changes on a different computer this command will update your working copy to include the changes. Go to your local working copy directory and type
svn update # replaces copies of files on your computer with the latest version
Make your changes. The most common changes that you'll make are edits to the contents of your existing files. But sometimes you need to add, remove, copy and move files and directories—the svn add, svn delete, svn copy, and svn move commands mange those changes within the working copy.
# Create a test.txt file and save it in the trunk in order to test the following
# commands
# Add the file
svn add test.txt
# To delete from the repository
svn delete test.txt
# If you want to copy a file under version control and create a new one
svn copy test.txt myTest.txt
# This is the same command you use to save a snapshot of the whole project by creating # a tag
svn copy https://subversion.assembla.com/svn/YOURPROJECTNAME/trunk \
https://subversion.assembla.com/svn/YOURPROJECTNAME/tags/v-0.0.1 -m "Saving the state
of the project before I started using Subversion."
# Adding directories
svn mkdir Data
Review your changes. The svn status and svn diff commands are critical to reviewing the changes you've made in your working copy.
# You can see what changes you made to the project with the status command
svn status
# svn status -v shows the status of all files, not just the ones with recent changes
On the off chance you make a change to a file that you don't like you can revert back to its previous state.
svn revert changedFile.text
Conflicts. A time may come when you run into version conflicts. If you make a change to a file that someone else is working on subversion will tell you about it. You will need to integrate these changes in order to avoid a file getting out of date. In this scenario you may see something like the following after running svn update
Conflict discovered in 'test.txt'.
Select: (p) postpone, (df) diff-full, (e) edit,
(mc) mine-conflict, (tc) theirs-conflict,
(s) show all options: p
C test.txt
Updated to revision 2.
# Your options
(e) edit - change merged file in an editor
(df) diff-full - show all changes made to merged file
(r) resolved - accept merged version of file
(dc) display-conflict - show all conflicts (ignoring merged version)
(mc) mine-conflict - accept my version for all conflicts (same)
(tc) theirs-conflict - accept their version for all conflicts (same)
(mf) mine-full - accept my version of entire file (even non-conflicts)
(tf) theirs-full - accept their version of entire file (same)
(p) postpone - mark the conflict to be resolved later
(l) launch - launch external tool to resolve conflict
(s) show all - show this list
Publish (commit) your changes. The svn commit command transmits your changes to the repository where they create the newest versions of all the things you modified. Now when others update they will see these changes!
svn commit test.txt
Using Subversion through a UI
Not everyone is comfortable working from the command line. For those of you who glazed over the previous section hopefully this will make up for it. There are many Subversion interfaces available. I will quickly show how to use a couple of the most popular.
Linux API
TortoiseSVN is the most popular interface for using Subversion on Linux platforms. 32 and 64 bit versions can be downloaded at http://tortoisesvn.net/downloads.html.
Mac Users API
Versions is a popular Subversion client for OSX. There is a free trial available for download at
http://versionsapp.com/. If you fall in love with this sleek interface it can be yours for $59. After downloading, open Versions and click "New Repository Bookmark".

A box with the following fields will appear
Enter the name of your project and the svn URL for location. Remember the location of your project can be found on your Assembla page under the svn tab. Don't forget to add trunk to this URL. Should look like https://subversion.assembla.com/svn/YOURPROJECTNAME/trunk. After you "Create" your Repository bookmark all your files hosted at the project URL will be visible in Versions on the left hand bookmarks panel.
To create a local working copy of the project you need to check out the code. The checkout button is in the top left corner of the Versions frame. After you check out your project a new folder containing the local working copy will appear below the project bookmark in the left hand panel of the Versions window.
When changes are made to any files in the working copy a pencil will appear next to them under the "Browse" tab. You can commit the changes by the selecting the file and hitting the "Commit" button in the top left corner (next to checkout). The first time you commit a change you will be prompted to re-enter your Assembla username and password. All commands outlined in the previous basic workflow section are available in the Versions interface.
Resources and Wrap Up